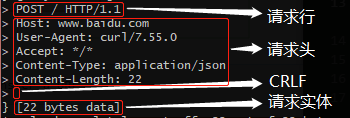
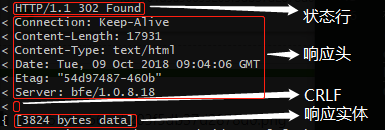
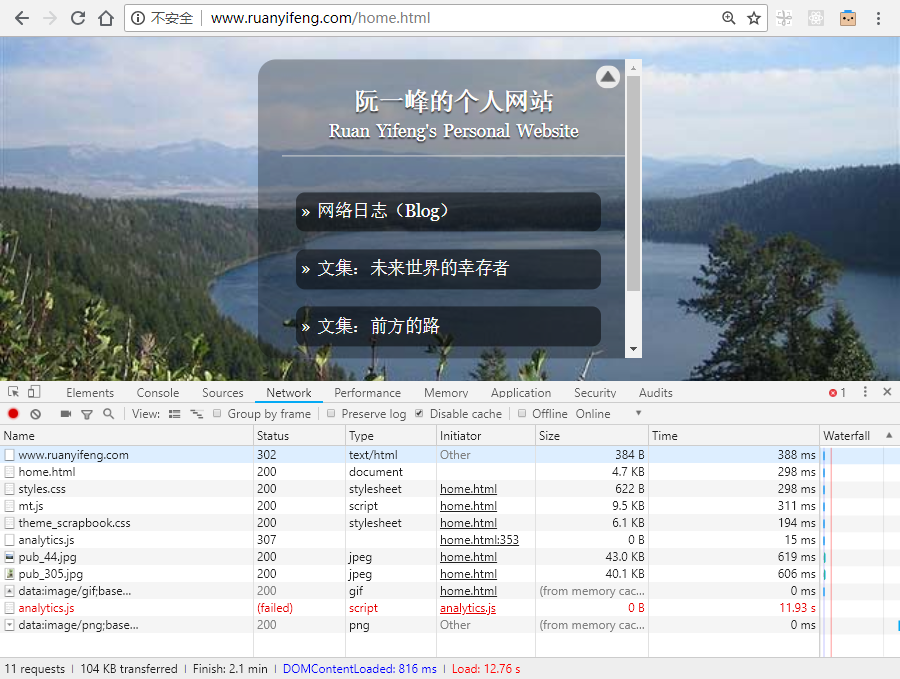
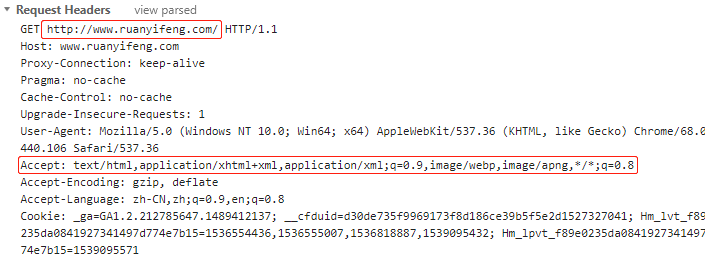
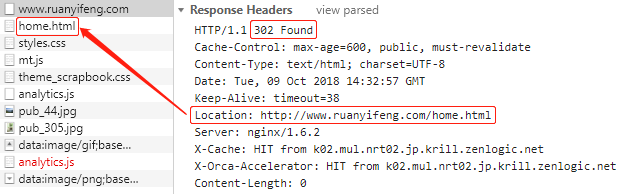
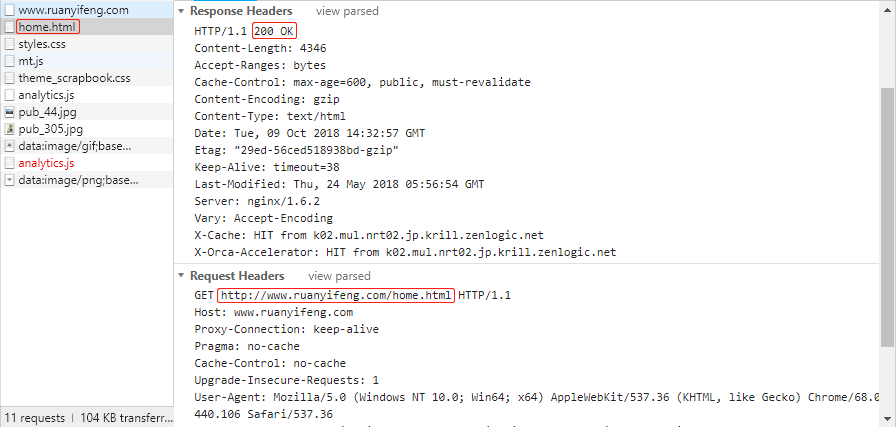
var hundred1 = { id: 'AA00000000', value: 100, unit: '元', color: '红', form: '纸币', issue: '2019-01', 兑换等值商品: function () {}, 换两张50块: function () {} } var hundred2 = { id: 'AA00000001', value: 100, unit: '元', color: '红', form: '纸币', issue: '2019-01', 兑换等值商品: function () {}, 换两张50块: function () {} }
于是我就可以用这两百块钱去吃椰子鸡了。
构造函数 & 原型对象
哎呀,椰子鸡好吃,可是钱也花光了。不行,我得再造钱来用,但我不想让别人看到我是怎么造的!所以我要做一个百元印钞机,把这些过程放百元进印钞机里,我只要输入每张钞票的 ID ,再按印刷键,就可以刷刷刷出百元大钞🤤。同时,这个印钞机要智能一点,不要老是一个个重复得去刻面额、单位、喷颜色等,直接给它引用个百元钞模版,这样能省点墨水😎。
哇,跟百元印钞机好像哦。说不定把它们整一下,就可以弄出一元印钞机、十元印钞机…… 那么我就弄个造钱机,它造的钱都有 兑换等值商品 的功能,我要让 N 元印钞机和 N 角硬币机在不需要自己定义的情况下就能直接用到它爸爸造钱机的 兑换等值商品 功能以及一些属性。这就是我们所谓的「继承」——让子类实例能够拥有父类实例的所有方法。
好吧,又得拿出第一节的例子… 我们尝试取你的长相是什么值,结果返回是“奇丑无比”,为什么不是“美丽动人”呢!!?(自己心里没点 B tree 吗)。请看下图,不记得老天报复把你变丑了吗?你在自身属性中找到了你的长相,你看到是“奇丑无比”,天空突然电闪雷鸣、雷雨交加,你哭倒在厕所,无力去走原型链找你的最初的样子,于是一蹶不振接受了这个事实(苍天绕过谁)。
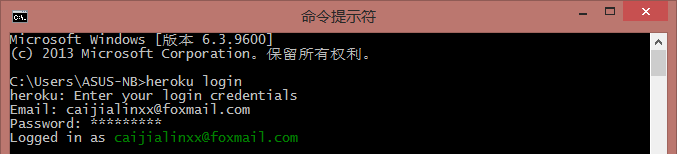
$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file inwhich to save the key (C:\Users\ASUS-NB\.ssh\id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in C:\Users\ASUS-NB\.ssh\id_rsa. Your public key has been saved in C:\Users\ASUS-NB\.ssh\id_rsa.pub. ...
然后, heroku keys:add 将公钥上传到 Heroku ,它会询问你是否确定上传,输入 y 即可:
1 2 3 4
$ heroku keys:add Found an SSH public key at C:\Users\ASUS-NB\.ssh\id_rsa.pub Would you like to upload it to Heroku? [Y/n]: y Uploading C:\Users\ASUS-NB\.ssh\id_rsa.pub SSH key... done
最初,网页只会在 PC 端展现,所以页面宽度是适应大多数 PC 端的。后来,随着智能手机(iPhone 3GS)的出现,原本为 PC 端设计的网页在小屏的手机上就“胖到挤不下”,用户只能不断移动这些网页来达到浏览的目的。后来乔布斯的工程师想了一个办法:他们让手机宽度模拟成 980px ,这样页面就能缩小了,用户想要浏览某个部分只需要手动放大。 但是随着智能手机的普及,这种不方便用户的功能显然不够贴心。 <meta name='viewport'> 的出现就是为了解决这个问题: